1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from LogisticsRegression import *
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
#读取数据,csv文件中最后一列为标签值,其他列都为特征值(这里带入自己的数据即可,注意每个变量代表的含义)
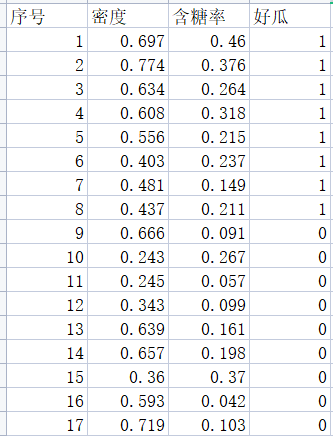
data = pd.read_excel('西瓜.xlsx')
#提取特征值和标签值
X = data.iloc[:,1::-1]
y = data.iloc[:,-1]
#对数据进行标准化
#mean/std可以查一查csdn
X = (X-np.mean(X,axis=0))/np.std(X,axis=0)
#对特征值加一列x0,x0的所有值为1,相当于偏离值b的系数,西瓜书上有
X = np.hstack([np.ones(shape=(len(X),1)),X])
#划分训练集与测试集,参数test_size设为0.2,random_state设为42
#这里借用了机器学习的处理
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 42)
#建立模型,并训练模型
Lr = LogisticsRegression()
Lr.GD(x_train,y_train)
#输出的是w1,w2,b三个参数
print("w1,w2,b=",Lr.theta)
#用测试数据集进行预测
predict = Lr.predict(x_test)
print("预测集:",predict)
print("真值:",np.array(y_test))
#评估预测的准确率
score = score(y_test,predict)
print("准确率:",score)
|