
基于大数据方法的豆瓣电影短评分类、预测与搜索(四):了解NLP的卷积神经网络
了解NLP的卷积神经网络
当我们听到卷积神经网络(CNN)时,我们通常会想到计算机视觉。CNN负责图像分类的重大突破,并且是当今大多数计算机视觉系统的核心,从Facebook的自动照片标记到自动驾驶汽车。
最近,我们也开始将CNN应用于自然语言处理中的问题,并得到了一些有趣的结果。在这篇文章中,我将尝试总结CNN是什么,以及它们如何在NLP中使用。对于计算机视觉用例来说,CNN背后的直觉更容易理解,所以我将从那里开始,然后慢慢转向NLP。
什么是卷积?
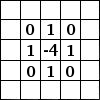
对我来说,理解卷积的最简单方法是将其视为应用于矩阵的滑动窗口函数。这很拗口,但看可视化就很清楚了:
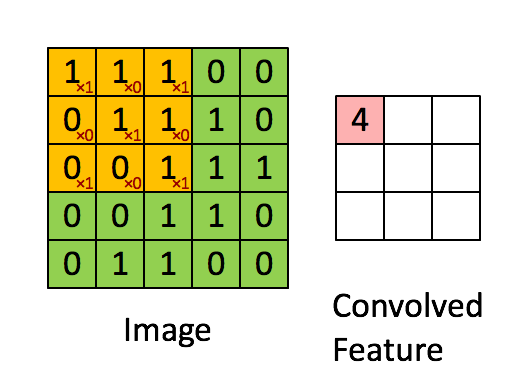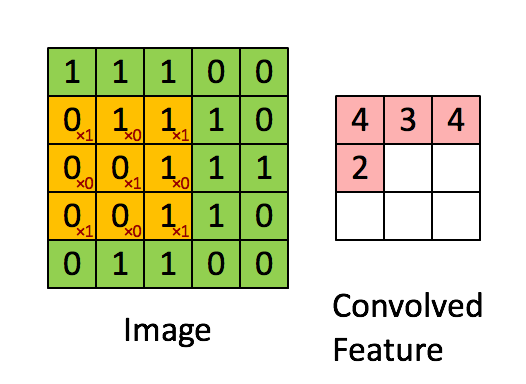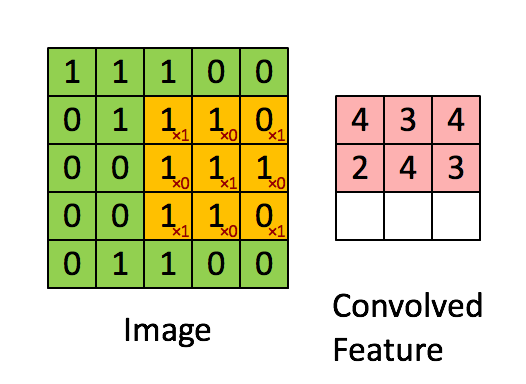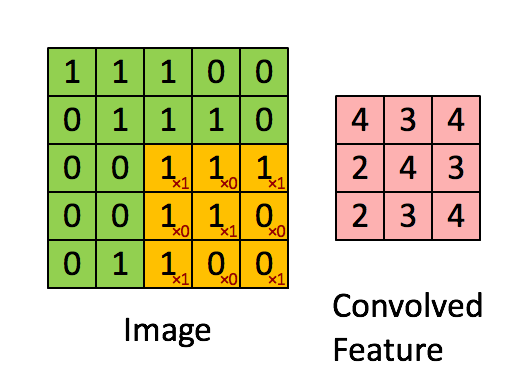
带 3×3 滤波器的卷积,来源:http://deeplearning.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/
想象一下,左边的矩阵表示一个黑白图像。每个条目对应一个像素,0 表示黑色,1 表示白色(灰度图像通常在 0 到 255 之间)。滑动窗口称为内核、过滤器或特征检测器。在这里,我们使用 3×3 过滤器,将其值逐个乘以原始矩阵,然后将它们相加。为了获得完整的卷积,我们通过在整个矩阵上滑动过滤器来为每个元素执行此操作。
您可能想知道您实际上可以用它做什么。以下是一些直观的例子。
将每个像素与其相邻值求平均值会使图像模糊:


取像素与其相邻像素之间的差异可检测边缘:
(要直观地理解这一点,请考虑图像中平滑的部分会发生什么,其中像素颜色等于其相邻颜色的颜色:添加取消,结果值为 0 或黑色。如果强度有锋利的边缘,例如从白色到黑色的过渡,你会得到很大的差异和由此产生的白色值)

什么是卷积神经网络?#
现在你知道什么是卷积了。但是CNN呢?CNN本质上是几层卷积,其中非线性激活函数(如ReLU)或tanh)应用于结果。在传统的前馈神经网络中,我们将每个输入神经元连接到下一层的每个输出神经元。这也称为全连接层或仿射层。在CNN中,我们改为在输入层上使用卷积来计算输出。这会导致本地连接,其中输入的每个区域都连接到输出中的一个神经元。每个图层应用不同的过滤器,通常为数百或数千个,如上所示,并组合其结果。还有一些东西叫做池化(子采样)层,但我稍后会谈到这一点。在训练阶段,CNN 会根据您要执行的任务自动学习其过滤器的值。例如,图像分类 CNN 可以学习从第一层中的原始像素检测边缘,然后使用边缘检测第二层中的简单形状,然后使用这些形状来阻止更高级别的特征,例如较高层中的面部形状。最后一层是使用这些高级功能的分类器。
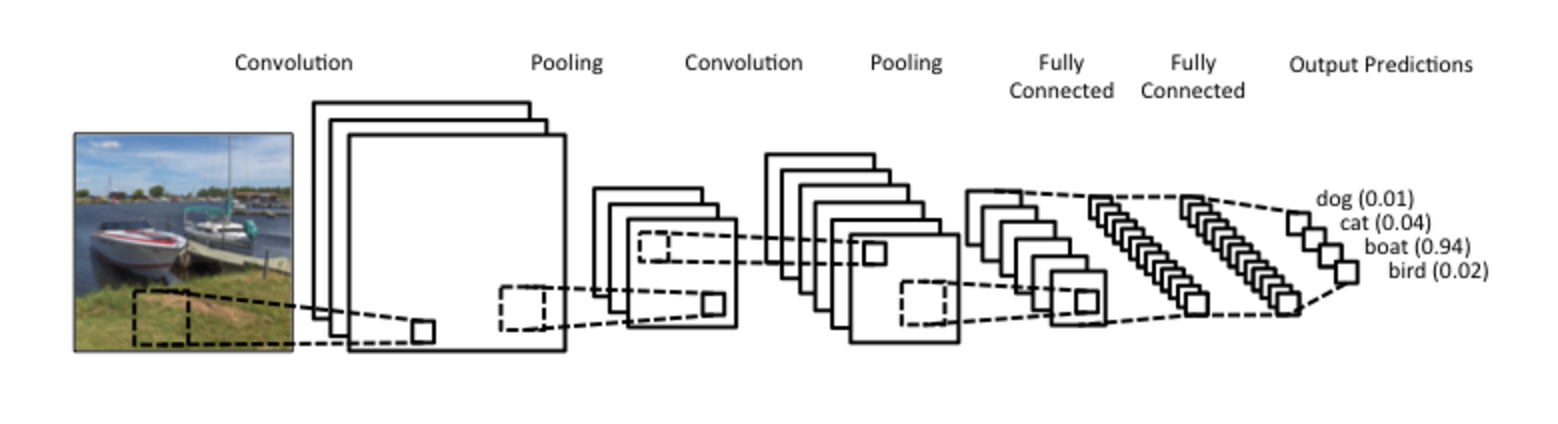
这种计算有两个方面值得关注:位置不变性和**组合性*。假设您要对图像中是否存在大象进行分类。因为你在整个图像上滑动滤镜,所以你并不真正关心大象出现在哪里。在实践中,池化还可以为您提供平移、旋转和缩放的不变性,但稍后会详细介绍。第二个关键方面是(局部)组成性。每个过滤器将*较低级别要素的局部修补程序组成为更高级别表示形式。这就是为什么CNN在计算机视觉中如此强大的原因。从像素构建边缘、从边缘构建形状以及从形状构建更复杂的对象,这很直观。
那么,这些如何适用于NLP?
大多数NLP任务的输入不是图像像素,而是表示为矩阵的句子或文档。矩阵的每一行对应于一个标记,通常是一个单词,但它可以是字符。也就是说,每一行都是表示一个单词的向量。通常,这些向量是词嵌入(低维表示),如word2vec或GloVe,但它们也可能是将单词索引为词汇表的单热向量。对于使用 10 维嵌入的 100 个单词的句子,我们将有一个 10×100 矩阵作为我们的输入。这就是我们的“形象”。
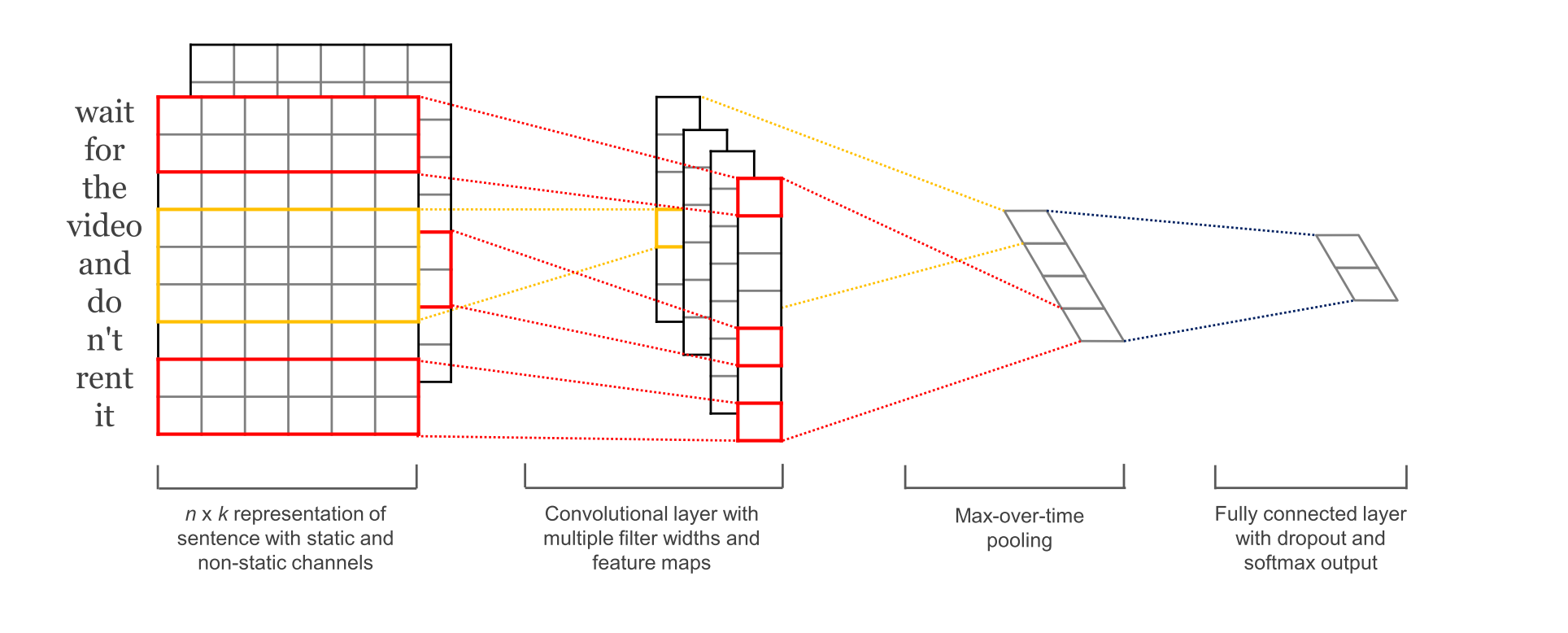
在视觉中,我们的过滤器在图像的局部斑块上滑动,但在NLP中,我们通常使用在矩阵(单词)的整行上滑动的过滤器。因此,过滤器的“宽度”通常与输入矩阵的宽度相同。高度或区域大小可能会有所不同,但一次超过 2-5 个单词的滑动窗口是典型的。综上所述,NLP 的卷积神经网络可能如下所示(花几分钟时间尝试理解这张图片以及如何计算维度。您现在可以忽略池化,稍后我们将解释):
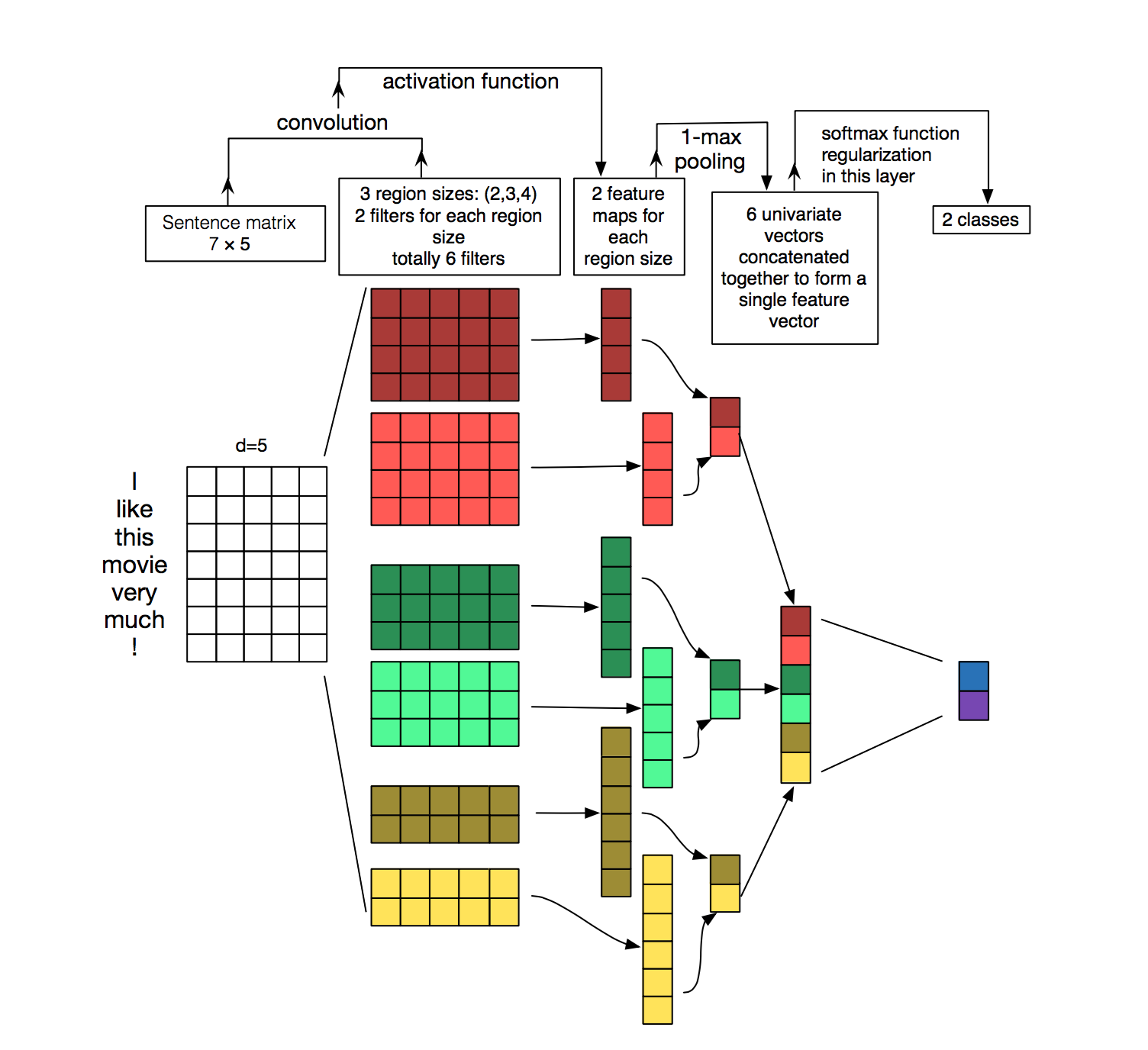
用于句子分类的卷积神经网络 (CNN) 架构图示。在这里,我们描述了三个过滤器区域大小:2、3 和 4,每个都有 2 个过滤器。每个过滤器对句子矩阵执行卷积并生成(可变长度)特征图。然后对每个图执行 1-max 池化,即记录每个特征图中的最大数量。因此,从所有六个映射生成一个单变量特征向量,并将这 6 个特征连接起来形成倒数第二层的特征向量。然后,最终的softmax层接收此特征向量作为输入,并使用它来对句子进行分类;这里我们假设二元分类,因此描述了两种可能的输出状态。资料来源:hang, Y., & Wallace, B. (2015).用于句子分类的卷积神经网络的敏感性分析.
我们对计算机视觉的直觉呢?位置不变性和局部组合性对于图像来说很直观,但对于NLP来说就不那么重要了。你可能非常关心句子中出现单词的位置。彼此接近的像素可能在语义上相关(同一对象的一部分),但对于单词并不总是如此。在许多语言中,短语的某些部分可以用其他几个单词分隔。构图方面也不明显。显然,单词以某些方式组成,例如修饰名词的形容词,但这究竟是如何工作的,更高层次的表示实际上“意味着”并不像计算机视觉案例那样明显。
考虑到这一切,CNN似乎不适合NLP任务。递归神经网络更直观。它们类似于我们处理语言的方式,或者至少是我们认为我们处理语言的方式:从左到右依次阅读。幸运的是,这并不意味着CNN不起作用。所有模型都是错误的,但有些模型是有用的。事实证明,应用于NLP问题的CNN表现得非常好。简单的Bag of Words模型显然过于简单,假设不正确,但多年来一直是标准方法,并产生了相当好的结果。
CNN的一个重要论点是它们速度很快。非常快。卷积是计算机图形学的核心部分,在 GPU 上的硬件级别实现。与n-grams相比,CNN在表示方面也很有效。对于大量词汇,计算超过 3 克的任何东西很快就会变得昂贵。甚至谷歌也没有提供超过5克的任何东西。卷积过滤器会自动学习良好的表示,而无需表示整个词汇表。使用大于 5 的过滤器是完全合理的。我喜欢认为第一层中的许多学习过滤器捕获的特征与 n 元语法非常相似(但不限于),但以更紧凑的方式表示它们。
CNN Hyperparameters
在解释如何将CNN应用于NLP任务之前,让我们看一下构建CNN时需要做出的一些选择。希望这将帮助您更好地了解该领域的文献。
Narrow vs. Wide convolution
当我在上面解释卷积时,我忽略了我们如何应用过滤器的一些细节。在矩阵中心应用 3×3 滤波器工作正常,但边缘呢?如何将过滤器应用于顶部和左侧没有任何相邻元素的矩阵的第一个元素?您可以使用零填充。所有落在矩阵之外的元素都被视为零。通过执行此操作,您可以将过滤器应用于输入矩阵的每个元素,并获得更大或相同大小的输出。添加零填充也称为宽卷积,不使用零填充将是窄卷积。1D 中的示例如下所示:
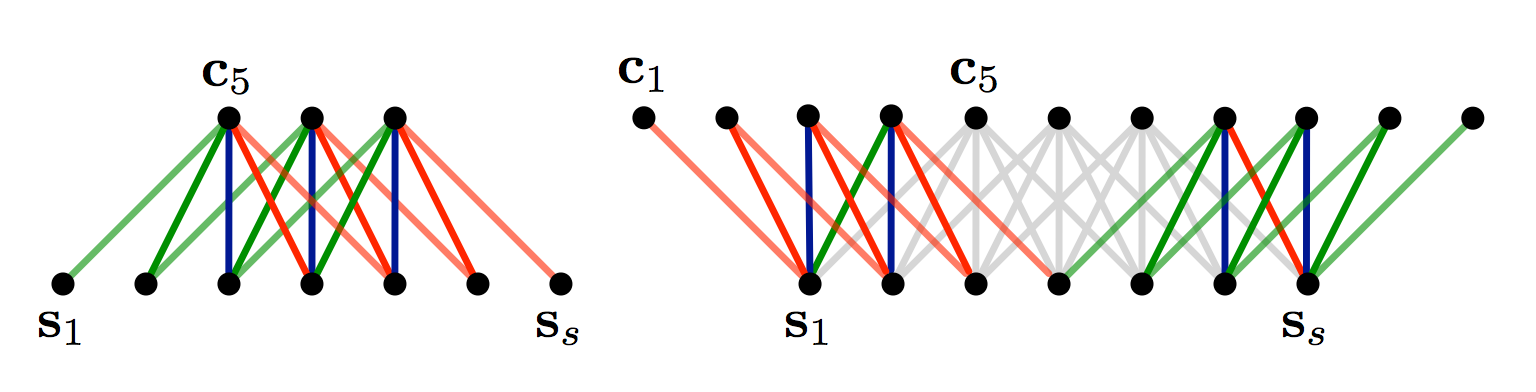
窄卷积与宽卷积。滤波器尺寸 5,输入尺寸 7。来源:用于句子建模的卷积神经网络(2014)
您可以看到,当您有一个相对于输入大小较大的过滤器时,卷积有多宽是有用的,甚至是必要的。在上面,窄卷积产生大小的输出(7−5)+1=3(7−5)+1=3,以及大小的宽卷积输出(7+2∗4−5)+1=11(7+2∗4−5)+1=11. 更一般地说,输出大小的公式为
Stride Size
卷积的另一个超参数是步幅大小,它通过您希望在每一步移动过滤器的程度来定义。在上述所有示例中,步幅均为 1,并且过滤器的连续应用重叠。步幅越大,滤波器的应用越少,输出尺寸越小。Stanford cs231 website以下内容显示了应用于一维输入的步幅大小 1 和 2:
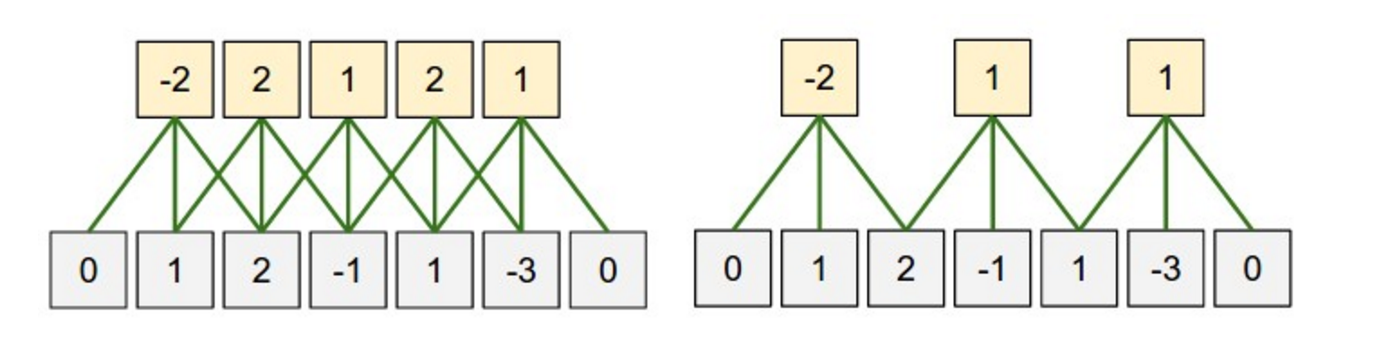
卷积步幅大小。左:步幅大小 1。右:步幅大小 2。来源: http://cs231n.github.io/convolutional-networks/
在文献中,我们通常看到步幅大小为 1,但更大的步幅大小可能允许您构建一个行为类似于递归神经网络的模型,即看起来像一棵树。
池化层
卷积神经网络的一个关键方面是池化层,通常在卷积层之后应用。池化层对其输入进行子采样。最常见的方法是将其池化以应用�一个�马·对每个筛选器的结果进行操作。您不一定需要在完整矩阵上池化,也可以在窗口上池化。例如,下面显示了 2×2 窗口的最大池化。在 NLP 中,我们通常对整个输出应用池化,每个滤波器只产生一个数字:
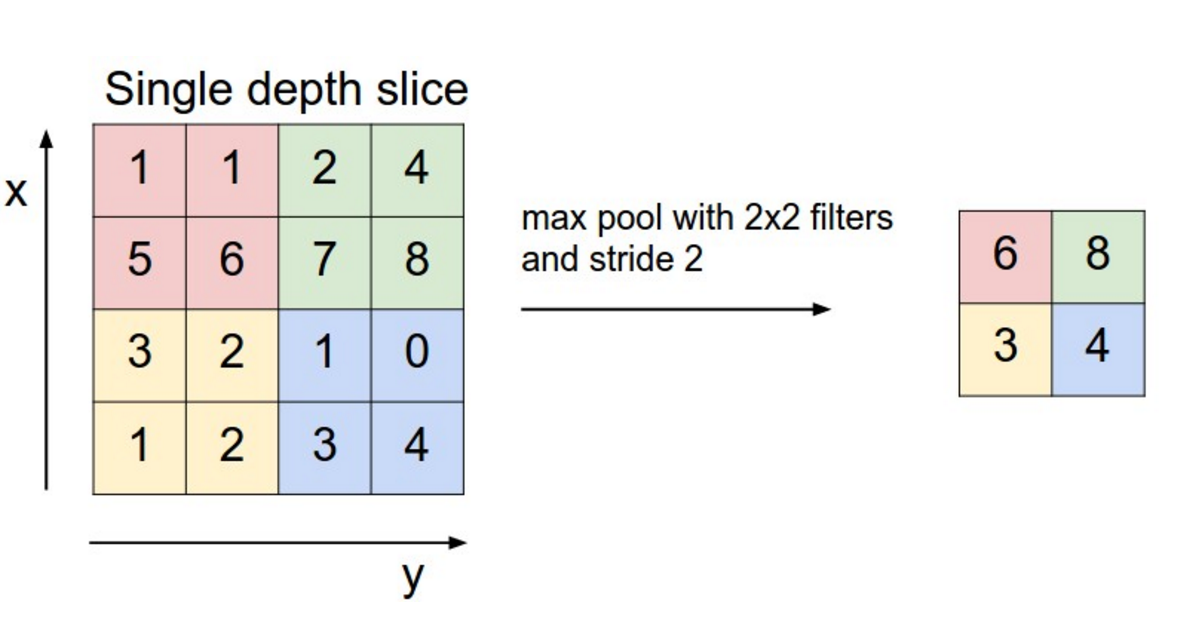
CNN 中的最大池化。来源: http://cs231n.github.io/convolutional-networks/#pool
为什么要池化?有几个原因。池化的一个属性是它提供固定大小的输出矩阵,这通常是分类所必需的。例如,如果您有 1,000 个筛选器,并且对每个筛选器应用最大池化,则无论筛选器的大小或输入的大小如何,都将获得 1000 维输出。这允许您使用可变大小的句子和可变大小的过滤器,但始终获得相同的输出维度以馈送到分类器中。
池化也会降低输出维度,但(希望)保留最突出的信息。您可以将每个过滤器视为检测特定特征,例如检测句子是否包含否定词,例如“不惊人”。如果此短语出现在句子中的某处,则对该区域应用筛选器的结果将产生较大的值,但在其他区域中将产生较小的值。通过执行 max 运算,您可以保留有关特征是否出现在句子中的信息,但您将丢失有关其确切显示位置的信息。但是,这些关于地点的信息真的没有用吗?是的,它是,它有点类似于一袋n-gram模型正在做的事情。您正在丢失有关局部性的全局信息(句子中发生某些事情的位置),但您保留了过滤器捕获的本地信息,例如“不惊人”与“惊人不惊人”非常不同。
在想象识别中,池化还为平移(移位)和旋转提供了基本的不变性。在某个区域上进行池化时,即使将图像移动或旋转几个像素,输出也将大致保持不变,因为无论如何,最大操作都会选择相同的值。
Channels
我们需要了解的最后一个概念是渠道。通道是输入数据的不同“视图”。例如,在图像识别中,您通常具有RGB(红色,绿色,蓝色)通道。您可以跨通道应用卷积,权重不同或相等。在NLP中,你也可以想象有各种各样的通道:你可以为不同的单词嵌入(例如word2vec和GloVe)提供一个单独的通道,或者你可以有一个通道来表示用不同的语言表示的同一个句子,或者用不同的方式表达。
卷积神经网络应用于NLP
现在让我们看看CNN在自然语言处理中的一些应用。我会尝试总结一些研究结果。我总是会错过许多有趣的应用程序,但我希望至少涵盖一些更受欢迎的结果。
最适合CNN似乎是分类任务,例如情绪分析,垃圾邮件检测或主题分类。卷积和池化操作会丢失有关单词本地顺序的信息,因此 PoS 标记或实体提取中的序列标记更难适应纯 CNN 架构(尽管并非不可能,您可以向输入添加位置特征)。
[1] 在各种分类数据集上评估 CNN 架构,主要由情感分析和主题分类任务组成。CNN架构在数据集上实现了非常好的性能,并在少数数据集上实现了最先进的性能。令人惊讶的是,本文中使用的网络非常简单,这就是它强大的原因。输入层是由连接的 word2vec 词嵌入组成的句子。接下来是具有多个过滤器的卷积层,然后是最大池化层,最后是softmax分类器。该论文还以静态和动态词嵌入的形式尝试了两种不同的通道,其中一个通道在训练期间进行调整,另一个则不调整。之前在 [2] 中提出了类似但稍微复杂的架构。[6] 在此网络架构中添加了一个执行“语义聚类”的附加层。
[4] 从头开始训练 CNN,无需像 word2vec 或 GloVe 这样的预先训练的词向量。它将卷积直接应用于独热向量。作者还为输入数据提出了一种节省空间的词袋状表示,减少了网络需要学习的参数数量。在[5]中,作者用额外的无监督“区域嵌入”扩展了模型,该嵌入是使用CNN预测文本区域上下文来学习的。这些论文中的方法似乎适用于长篇文本(如电影评论),但它们在短文本(如推文)上的表现尚不清楚。直观地说,对短文本使用预先训练的单词嵌入比对长文本使用它们会产生更大的收益是有道理的。
构建CNN架构意味着有许多超参数可供选择,其中一些我在上面介绍过:输入响应(word2vec,GloVe,one-hot),卷积过滤器的数量和大小,池化策略(最大值,平均值)和激活函数(ReLU,tanh)。[7] 对 CNN 架构中不同超参数的影响进行了实证评估,调查了它们对多次运行的性能和方差的影响。如果您希望实现自己的CNN进行文本分类,那么使用本文的结果作为起点将是一个好主意。一些突出的结果是,最大池化总是胜过平均池化,理想的过滤器大小很重要但取决于任务,并且正则化似乎在所考虑的NLP任务中没有太大的不同。这项研究的一个警告是,所有数据集在文档长度方面都非常相似,因此相同的准则可能不适用于看起来有很大差异的数据。
[8] 探索用于关系提取和关系分类任务的 CNN。除了词向量之外,作者还使用词与感兴趣实体的相对位置作为卷积层的输入。此模型假定给定实体的位置,并且每个示例输入都包含一个关系。[9]和[10]探索了类似的模型。
CNN在NLP中的另一个有趣的用例可以在[11]和[12]中找到,来自Microsoft Research。这些论文描述了如何学习可用于信息检索的句子的语义有意义的表示。论文中给出的示例包括根据用户当前正在阅读的内容向用户推荐可能感兴趣的文档。句子表示基于搜索引擎日志数据进行训练。
大多数CNN架构以一种或另一种方式学习单词和句子的嵌入(低维表示),作为其训练过程的一部分。并非所有论文都关注训练的这一方面或研究学习嵌入的意义。[13]提出了一个CNN架构来预测Facebook帖子的主题标签,同时为单词和句子生成有意义的嵌入。然后,这些学习的嵌入成功地应用于另一项任务 - 向用户推荐可能感兴趣的文档,并根据点击流数据进行训练。
Character-Level CNNs
到目前为止,所有提出的模型都是基于文字的。但也有人研究将CNN直接应用于角色。[14] 学习字符级嵌入,将它们与预先训练的词嵌入连接起来,并使用 CNN 进行词性标记。[15][16] 探索了使用 CNN 直接从角色中学习,而无需任何预先训练的嵌入。值得注意的是,作者使用了一个相对深度的网络,共有9层,并将其应用于情感分析和文本分类任务。结果表明,直接从字符级输入中学习在大型数据集(数百万个示例)上效果非常好,但在较小的数据集(数十万个示例)上表现不佳。[17] 探索了字符级卷积在语言建模中的应用,在每个时间步使用字符级 CNN 的输出作为 LSTM 的输入。相同的模型应用于各种语言。
令人惊讶的是,基本上上述所有论文都是在过去1-2年内发表的。显然,CNN之前在NLP方面已经有过出色的工作,就像从Scratch开始的自然语言处理(几乎)一样,但是新结果和最新系统发布的步伐显然正在加快
參考链接:
Understanding Convolutional Neural Networks for NLP · Denny’s Blog (dennybritz.com)
