
实验二:词频统计与可视化
实验二:词频统计与可视化
Design by W.H Huang | Direct by Prof Feng
1 实验目的
通过本次实验,你应该:
- 熟悉 hadoop+ Spark下编程环境
- 掌握基于Spark的基本MAP REDUCE 操作
- 掌握基本大数据可视化工具
- 独立完成本次青年群体择偶观分析实验
- 【新增】远程开发相关知识
本次实验需小组内分工合作完成两个任务:
WordCount 词频统计
你将会使用到 jieba 分词 & 基于 pySpark 的基本 MAP REDUCE 操作进行词频统计,在指定数据集上大数据分析青年群体择偶观倾向。
大数据可视化
你将使用 echars & WordCloud 两个可视化库来进行大数据可视化,小组独立完成核心代码编写、测试。
2 实验准备
2.0 成绩说明
本次实验,根据各位同学选择的不同环境搭建方式,不同的成绩分数说明如下。
【注】本次实验不要求使用分布式。
| 实验环境 | 最高分 |
|---|---|
| 云服务器 | 100 |
| VM虚拟机 | 95 |
在本次实验我们给予学有余力的同学,在完成本次实验的基础上提出了扩展要求。
【注】加分后总分不超过100分。
| 扩展要求 | 加分 | |
|---|---|---|
| 1. 使用分布式完成本次实验 | +5 | 可参考ex3~ex4 |
| 2. 扩充原有数据集(100M以上),或基于新的数据集进行实验 | +5~+10 | 根据数据量、质量、难度给分 |
| 3. 新增更多可视化,如柱状图等 | +5~+10 | 根据可视化工作量给分 |
| 4. 使用更好的算法分析数据,如应用深度学习模型Bert | +10 | 有对比实验最好 |
2.1 上传文件
在开始实验前, 首先要将代码及相关资源上传到服务器。该小节将介绍如何使用FTP软件将本地(Windows)文件上传到服务器(Linux)。
下载软件
FTP工具我们选择
Filezilla,下载地址:Filezilla下载
点击进行下载安装,安装过程较为简单不再赘述。
连接服务器
依次点击:文件 —> 站点管理器 —> 新站点

上传文件
如下图所示,左侧为本地文件,右侧为服务器文件目录(默认为
/home/hadoop)
上传完毕后,可在服务器上查看文件:

2.2 【强烈建议】远程开发
教程支持:@white_windmills @Wanghui-Huang @ghc2000
- 云环境:基于华为云,腾讯云/阿里云也可
- 操作系统:基于Ubantu,CentOS下也可
在教程ex0 & 2.1节时,我们介绍了:
SSH工具,如Xshell,可以很方便在终端命令行操作远程服务器;FTP工具,如Filezilla,可以很方便的上传/下载数据集和代码等;
但是因为代码运行环境在远程服务器上,我们只能这么进行代码编写、调试:
Filezilla上传数据集等资源;Xshell连接服务器命令行操作,使用vim编写代码,关键地方print;- 编写好后命令行下执行
python code.py,观察代码print输出 & 调试。
显然这样做效率是很低下的。或者你还想到:
- VNC登陆云服务器,安装桌面、IDE等;
- 在VNC中云桌面编写代码。
但这种做法经过实际尝试也是不建议的:
- 资源问题:安装桌面要消耗服务器很大的资源,对于本来就资源不足的丐版云服务器雪上加霜;
- 操作问题:VNC桌面登陆,复制、粘贴等基本操作都很麻烦,不太方便;
- 网络问题:实际操作下,网络延迟有时比较大,加上启动桌面很耗资源,经常会卡成PPT。
因此对于实际开发来说,我们还是更希望能使用本地IDE去调试远程代码,而不是使用vim或者直接远程服务器安装IDE。
那么,如何在本地电脑使用IDE去调试远程机器上的代码?
- 现在我们可以在VSCode/Pycharm 进行远程开发相关配置;
- VSCode/Pycharm 等IDE通常还集成了终端环境,方便我们操作服务器。
正式开始前,我们先检查一下SSH安装情况。
查看是否安装了ssh-server服务
非云系统默认只安装ssh-client服务。
1
dpkg -l | grep ssh

华为云等云厂商一般还会默认安装ssh-server服务,如果没有:
1
sudo apt-get install openssh-server
确认ssh-server启动
1
ps -e | grep ssh

如果看到
sshd,说明ssh-server已经成功启动。特别的,我们设置一下允许密码登陆root用户:
1
vim /etc/ssh/sshd_config
- 注释配置文件中的
PermitRootLogin without-password,即前面加一个#号 - 增加
PermitRootLogin yes一行
最后重启服务:
1
2sudo /etc/init.d/ssh stop
sudo /etc/init.d/ssh start- 注释配置文件中的
2.2.1 VSCode远程开发实践
安装Remote-SSH插件
左侧Extension图标 —-> 输入
Remote-SSH—->安装即可。注意,需要远程和本地都进行安装。
配置Remote-SSH插件
如图所示选择
.ssh/config文件进行配置: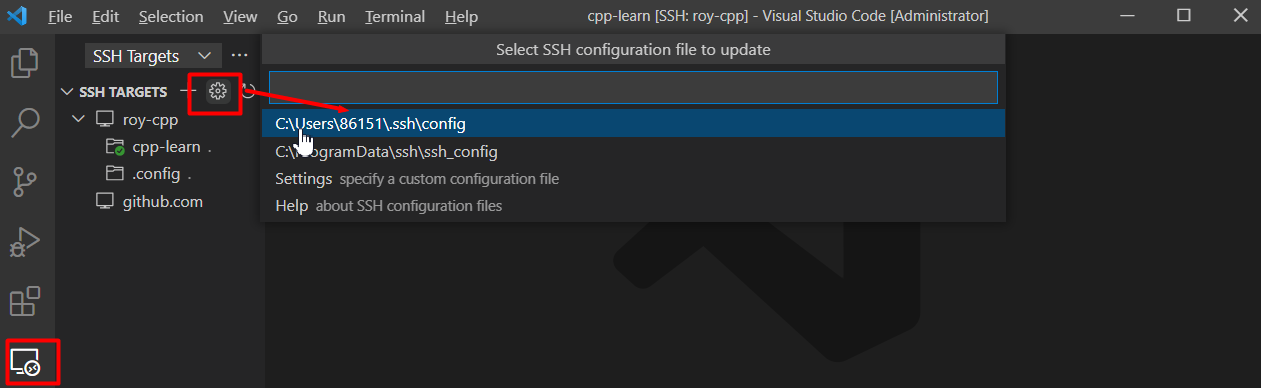
打开文件后,需要设置以下字段:
- Host:自定义即可
- HostName:云主机公网IP
- User:登陆的用户,选择root
- IdentityFile:免密登录私钥地址,如果没有配置则每次远程登录需要输入密码
以下为示例:
1
2
3
4Host roy-cpp
HostName 121.36.59.23 # 云主机公网IP
User root
IdentityFile D:/huawei_rsa/id_rsa # 这行可删除登陆测试
点击下图按钮进行登陆:
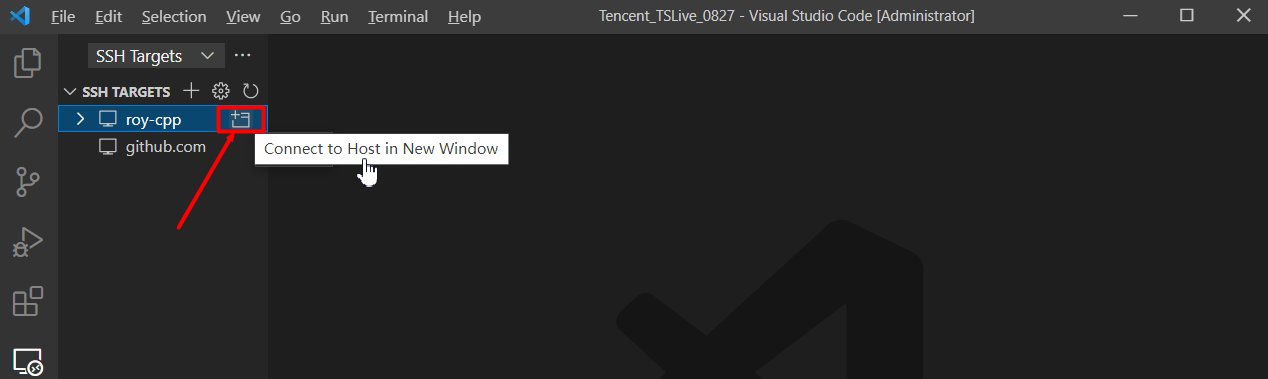
输入密码后,便可以看到远程服务器已经成功连接。
远程开发实践
连接上后就和我们本地使用VSCode没有什么区别:
打开远程文件:File—->Open Folder—->指定文件夹路径,类似打开本地文件;
使用终端:在VSCode下方
Terminal一栏可进行命令行操作,可认为是一个ssh连接的界面,你可以在上面进行之前Xshell等软件的所有操作;
远程debug:使用
python插件,注意远端&本地都要安装。
2.2.2 Pycharm远程开发实践
在Pycharm中此功能需要用专业版,正版的话直接去官网学生申请即可(我们重大的邮箱没法申请,需要拍学生证申请)。
SSH配置
打开File->Settings->SSH Configurations,进行如下配置:

输入完成后,点击Test Connection,测试一下连接状态
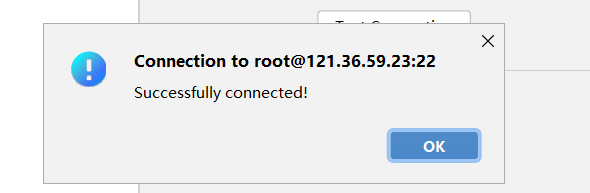
新建SSH Session
点击:Tools—->Start SSH Session…—->Edit credentials,现在可以进行对服务器的命令行操作(可以视作之前的ssh窗口):
仅仅使用命令行是肯定不够的,pycharm提供了很多更便捷的工具。
配置远端python解释器
点击:File—->Settings—->Project:…—>Project Interpreter,添加python解释器:
选择SSH Interpreter,选择刚刚配置好的服务器:
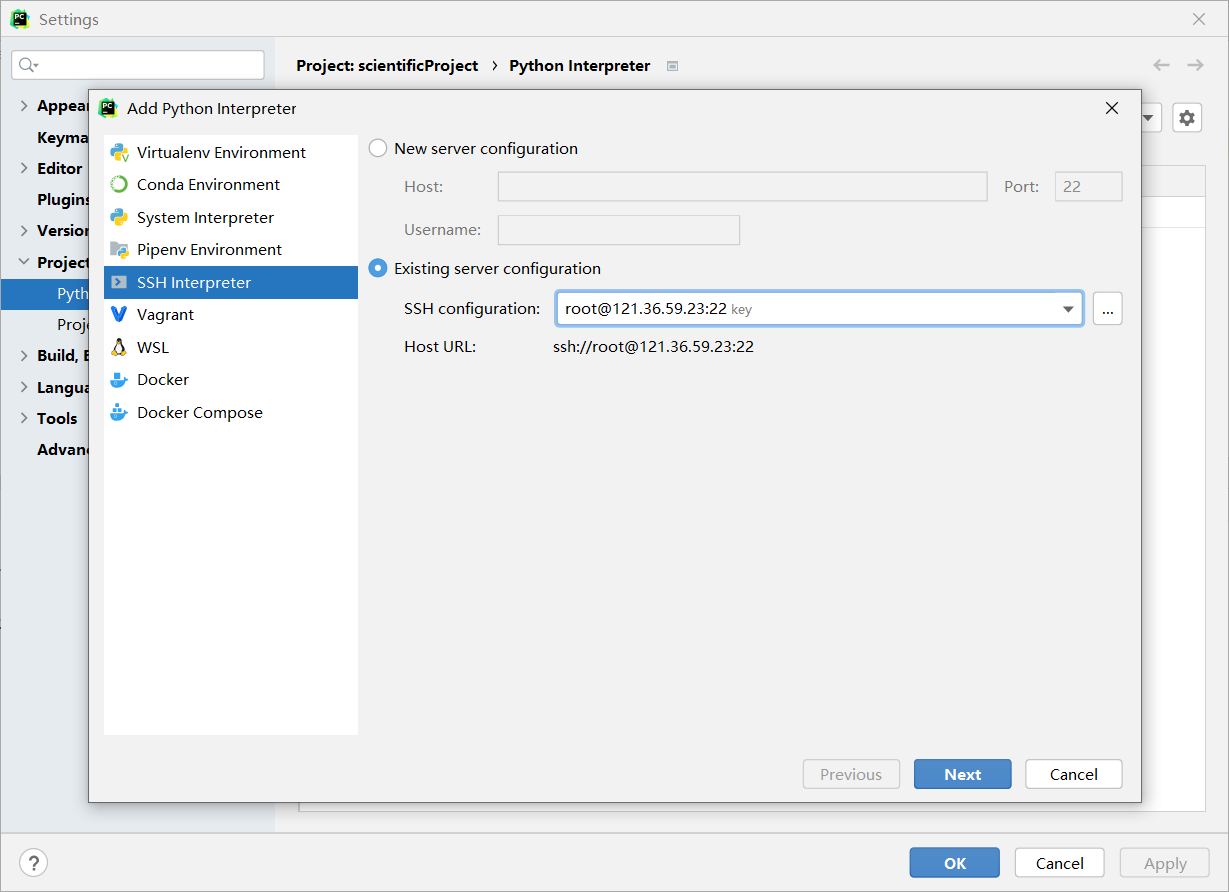
选择服务器中你需要的解释器,以及项目文件的映射路径,勾选自动同步等配置:

配置完成后就和本地解释器的使用差不多了:
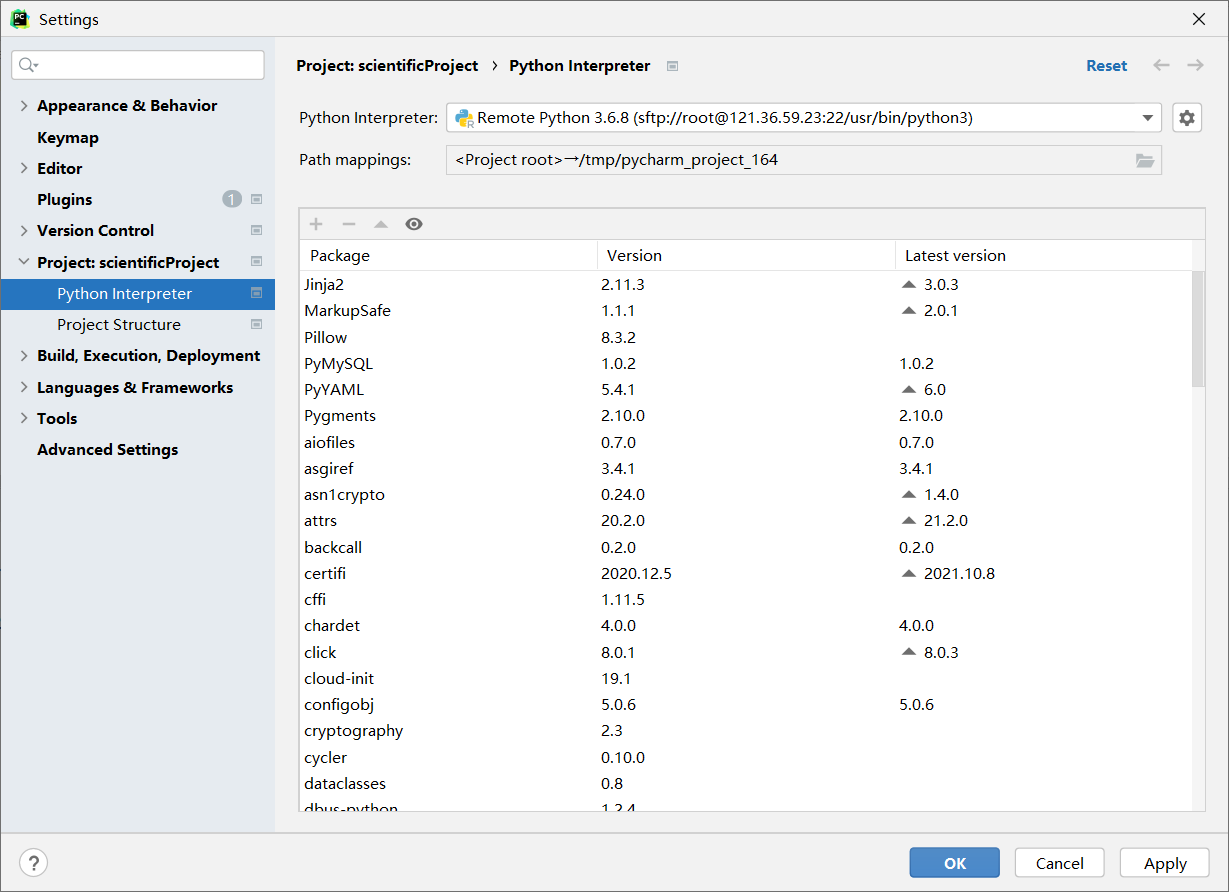
特别的如果需要修改映射路径可以在:tools->Deployment->Configurations,下进行修改。
打开远端目录
通过:tools—>Deployment—>Configurations—>Browse Remote Host,打开远端目录文件树。
之后就可以操作远程目录的文件:
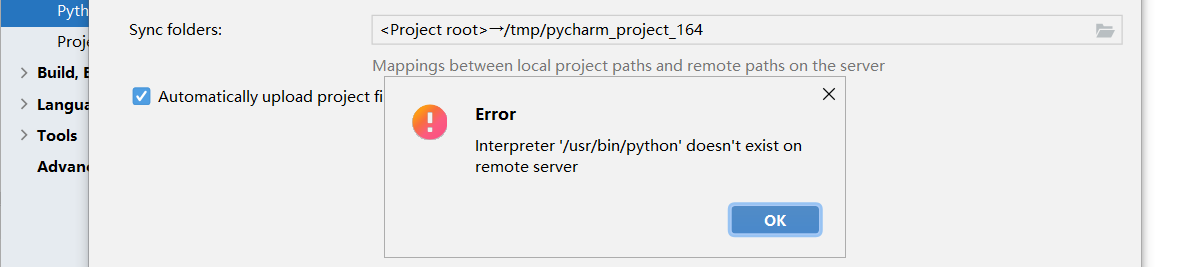
问题解决
[ERROR#1] 远端解释器连接失败。
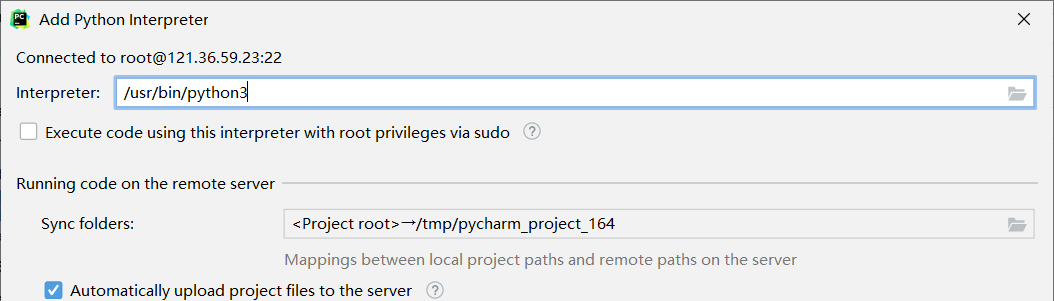
一般是因为解释器路径写错了,很多系统默认装的是python3,修改解释器路径即可:
[ERROR#2] 华为云的openEuler系统ssh连不上。
可能是服务器设置问题,需要修改/etc/ssh/sshd_config文件:
首先,运行如下命令
1
vi /etc/ssh/sshd_config
接着,我们要做如下修改
1
2
3AllowAgentForwarding yes
AllowTcpForwarding yes
GatewayPorts yes
2.2.3 扩展阅读:C++远程开发实践
最近在学C++,想配置C++远程开发环境?最好还能调试代码?
请参考:C++从零开始(一):环境搭建(上)之VSCode远程开发
2.3 安装相关库
:warning: 注意,本实验需要你安装桌面环境:请参考
ex0:2.1.2 可视化界面。
先更新pip ,否则可能会出现安装失败。
1 | sudo pip3 install --upgrade pip |
如果以下调用yum命令出错,请将以下两个文件的第一行改为python2/2.7。相关讨论可见:issue#23 。
修改urlgrabber-ext-down
1
sudo vim /usr/libexec/urlgrabber-ext-down

修改yum

下面开始正式安装本次实验所需的库文件。
安装字体文件
本次实验,需要wqy-microhei.ttc文件,但在
/usr/share/fonts可能并不存在该文件。需要自行安装:1
sudo yum install wqy-microhei-fonts
安装
jieba1
sudo pip3 install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
安装
wordcloud1
sudo pip3 install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple
安装
pyecharts需要指定安装1.7.0版本,否则下面代码API调用接口不正确。
1
2sudo pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts==1.7.0
sudo pip3 install snapshot-selenium安装驱动(易错)
pyechars模块保存图片需要安装相应chromedriver和google-chrome ,并且版本号要一一对应。安装google-chrome
1
2
3
4
5
6sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
sudo curl https://intoli.com/install-google-chrome.sh | bash
ldd /opt/google/chrome/chrome | grep "not found"
google-chrome --no-sandbox --headless --disable-gpu --screenshot https://www.baidu.com/安装chromedrive
chromedrive版本要和google-chrome对应,所以我们先查看google-chrome版本号:
1
google-chrome-stable --version
记录版本号后,去https://npm.taobao.org/mirrors/chromedriver/ 下载对应的驱动。下载方式:
推荐:
wget 下载链接形式 ,例如下载95版本的chromedriver1
sudo wget -O chromedriver_linux64.zip https://npm.taobao.org/mirrors/chromedriver/107.0.5304.62/chromedriver_linux64.zip
笨一点:本地机器下载后,使用FTP工具上传到服务器
下载后,在下载的压缩文件所在的路径:
1 | # 1. 先删除之前的chromedriver |
2.4 设置日志级别
由于
spark在运行时会打印非常多的日志,为了便于调试观察,我们设置日志级别为WARN。
以下为全局设置日志级别方式,你也可在代码中临时设置 sc.setLogLevel("WARN") (详见ex3.pdf)。
切换到
conf目录1
cd /usr/local/spark/conf
设置配置文件
1
2cp log4j2.properties.template log4j.properties
vim log4j2.properties1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89status = error
property.LOG_HOME=/output/logs
property.BACKUP_HOME=backup
property.SERVER_NAME=buddie-Service
property.EVERY_FILE_SIZE=10M
property.OUTPUT_LOG_LEVEL=INFO
property.FILE_MAX=10
appender.console.type = Console
appender.console.name = STDOUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %m%n
appender.rolling.type=RollingFile
appender.rolling.name=RollingFileAll
appender.rolling.filter.threshold.level = trace
appender.rolling.filter.threshold.type = ThresholdFilter
appender.rolling.fileName=${LOG_HOME}/dev_${SERVER_NAME}_all.log
appender.rolling.filePattern=${LOG_HOME}/dev_${BACKUP_HOME}/dev_${SERVER_NAME}_all.%d{yyyy-MM-dd-HH}.log
appender.rolling.layout.type=PatternLayout
appender.rolling.layout.pattern=%d %p %C{1.} [%t] %m%n
appender.rolling.policies.type=Policies
appender.rolling.policies.time.type=TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval=2
appender.rolling.policies.time.modulate=true
appender.rolling.policies.size.type=SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=${EVERY_FILE_SIZE}
appender.rolling.strategy.type=DefaultRolloverStrategy
appender.error.type=RollingFile
appender.error.name=RollingFileError
appender.error.filter.threshold.level = error
appender.error.filter.threshold.type = ThresholdFilter
appender.error.fileName=${LOG_HOME}/dev_${SERVER_NAME}_error.log
appender.error.filePattern=${LOG_HOME}/dev_${BACKUP_HOME}/dev_${SERVER_NAME}_error.%d{yyyy-MM-dd-HH}.log
appender.error.layout.type=PatternLayout
appender.error.layout.pattern=%d %p %C{1.} [%t] %m%n
appender.error.policies.type=Policies
appender.error.policies.time.type=TimeBasedTriggeringPolicy
appender.error.policies.time.interval=2
appender.error.policies.time.modulate=true
appender.error.policies.size.type=SizeBasedTriggeringPolicy
appender.error.policies.size.size=${EVERY_FILE_SIZE}
appender.error.strategy.type=DefaultRolloverStrategy
appender.charge.type=RollingFile
appender.charge.name=RollingFileCharge
appender.charge.filter.threshold.level = trace
appender.charge.filter.threshold.type = ThresholdFilter
appender.charge.fileName=${LOG_HOME}/dev_${SERVER_NAME}_charge.log
appender.charge.filePattern=${LOG_HOME}/dev_${BACKUP_HOME}/dev_${SERVER_NAME}_charge.%d{yyyy-MM-dd-HH}.log
appender.charge.layout.type=PatternLayout
appender.charge.layout.pattern=%d %p %C{1.} [%t] %m%n
appender.charge.policies.type=Policies
appender.charge.policies.time.type=TimeBasedTriggeringPolicy
appender.charge.policies.time.interval=2
appender.charge.policies.time.modulate=true
appender.charge.policies.size.type=SizeBasedTriggeringPolicy
appender.charge.policies.size.size=${EVERY_FILE_SIZE}
appender.charge.strategy.type=DefaultRolloverStrategy
logger.activity.name = buddie.activity
logger.activity.level = debug
logger.activity.additivity = false
logger.activity.appenderRef.all.ref = RollingFileAll
logger.activity.appenderRef.error.ref = RollingFileError
logger.activity.appenderRef.stdout.ref = STDOUT
logger.login.name = buddie.login
logger.login.level = debug
logger.login.additivity = false
logger.login.appenderRef.all.ref = RollingFileAll
logger.login.appenderRef.error.ref = RollingFileError
logger.login.appenderRef.stdout.ref = STDOUT
logger.charge.name = buddie.charge
logger.charge.level = trace
logger.charge.additivity = false
logger.charge.appenderRef.all.ref = RollingFileAll
logger.charge.appenderRef.error.ref = RollingFileError
logger.charge.appenderRef.charge.ref = RollingFileCharge
logger.charge.appenderRef.stdout.ref = STDOUT
rootLogger.level = info
rootLogger.appenderRef.stdout.ref = STDOUT
rootLogger.appenderRef.all.ref = RollingFileAll
rootLogger.appenderRef.error.ref = RollingFileError

3 实验流程
(已弃用)3.0 命令行下完成实验
:warning: 该小节编写、调试代码方式已被弃用,采用远程开发模式 :warning:
2021-12-20:建议大家使用远程开发,进行代码编写,实验调试等。远程开发教程请参考:2.2节 【强烈建议-远程开发】。
在实验开始之前,我们建议你按照以下流程完成实验:
- 命令行 下完成代码 单元测试
- 单元测试无误,将代码填充在相应给出的
py文件函数中 spark-submit方式提交代码
:slightly_smiling_face: 如何在命令行下完成单元测试?
启动
pyspark1
2cd /usr/local/spark
bin/pyspark:warning: 后续实验都是在集群环境下(本次实验不需要),启动
pyspark应该按以下方式:启动集群
1
2
3
4
5
6
7# 启动hadoop集群
cd /usr/local/hadoop
sbin/start-all.sh
# 启动spark集群
cd /usr/local/spark
sbin/start-master.sh
sbin/start-slaves.sh启动
pyspark1
bin/pyspark --master spark://master:7077
命令行下单元测试
例如,本次实验要求你完成
jiebaCut函数编写:完成下列指定位置编码,使得
str为所有答案拼接而成的字符串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def jiebaCut(answers_filePath):
"""
结巴分词
:param answers_filePath: answers.txt路径
:return:
"""
# 读取answers.txt
answersRdd = sc.textFile(answers_filePath) # answersRdd每一个元素对应answers.txt每一行
# 利用SpardRDD reduce()函数,合并所有回答
# 【现在你应该完成下面函数编码】
str = answersRdd.reduce(lambda )
# jieba分词
words_list = jieba.lcut(str)
return words_list:warning: 命令行模式下,不用设置
SparkContext、SparkSession实例:1
2conf = SparkConf().setAppName("ex2").setMaster("local")
sc = SparkContext(conf=conf)会自动生成实例
sc,可直接使用!首先定义
answers_filePath,查询此前代码指定按照如下方式进行拼接:
1
>>> answers_filePath = 'file:///home/hadoop/Experiment/Ex2_WordCount/src/answers.txt'
按照流程读入文件:
1
2>>> answersRdd = sc.textFile(answers_filePath)
>>> answersRdd.take(10) # 展示前10行数据验证现在你可以尝试在命令行下 实时交互 完成
str = answersRdd.reduce(lambda )这行代码完整编写。例如,你可以如此进行测试:
1
2>>> answersRdd.reduce(lambda a,b: a+b)
'★★★更新于4个月以后★7月14日晚★★★写这个答案时,刚刚过完春节,在家被催婚心烦意乱,随手刷到,一时兴起...'会实时显示交互结果,验证是否编码正确。
提交代码
在命令行下单元测试后,便可以填写在相应
py文件中。最后通过
spark-submit方式提交代码。相应如何提交,在实验后有详细介绍,这里不再赘述。
3.1 数据集介绍
本次实验数据集来源于2019级研究生@W.H. Huang,数据集包含了知乎全站 择偶观 相关问题下所有 答案 &作者&年龄&地区等信息 。原完整数据存储于
mysql数据库,出于简化实验数据部署等目的,本次实验仅使用其中部分数据以txt文本形式展示。
数据集 answers.txt 每一行代表一个完整回答,一共有3W条回答,如下图:

每一条回答均已去除图片、视频URL、HTML标签等。
3.2 WordCount.py
3.2.1 完成编码
你现在应该独立完成WordCount.py 编码,可在服务器上查看:
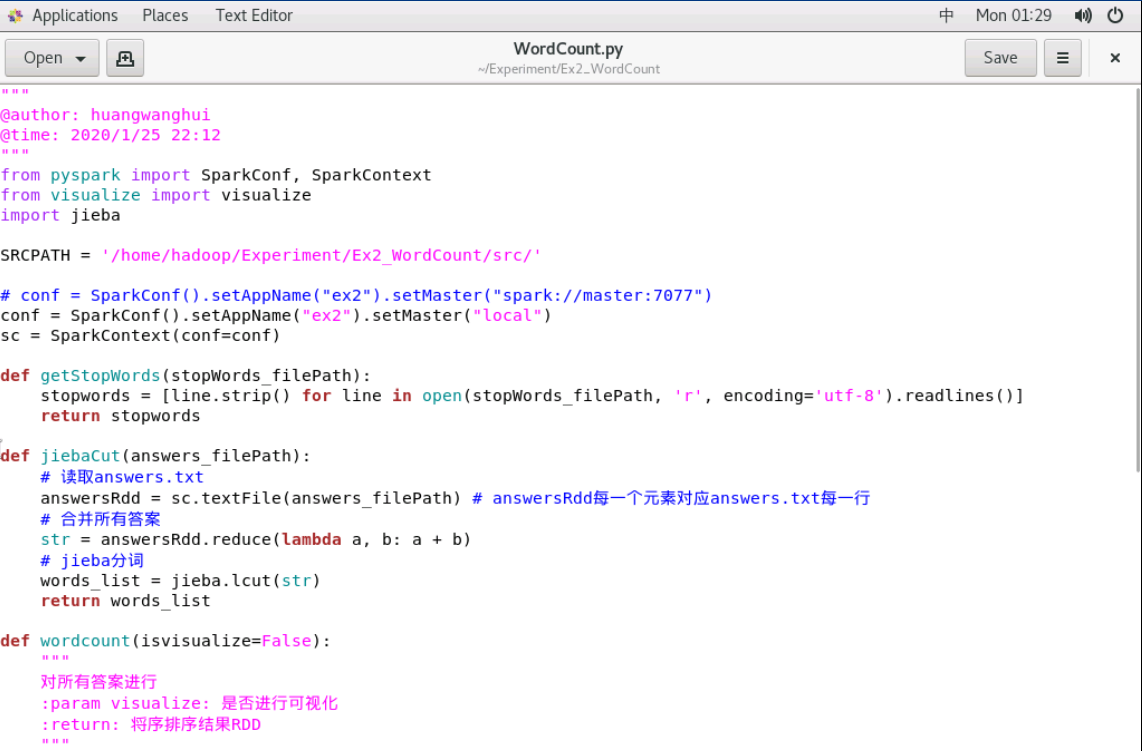
WordCount.py 有3个函数,它们的作用如下:
getStopWords:读取stop_words.txt所有停用词,返回一个python ListjiebaCut: 将所有答案合并,并进行分词,返回一个python Listwordcout: 核心函数,利用SparkRdd完成词频统计
jiebaCut
完成下列指定位置编码,使得str 为所有答案拼接而成的字符串
1 | def jiebaCut(answers_filePath): |
wordcout
完成下面指定位置编码,使得resRdd 包含所有词频统计结果,且降序排列。
打印resRdd 前十个元素应该为如下结果,resRdd.take(10) :

1 | def wordcount(isvisualize=False): |
3.2.2 提交代码
此时主函数代码,设置可视化为False:
1 | if __name__ == '__main__': |
切换到
spark目录1
cd /usr/local/spark
提交代码(单机模式)
1
bin/spark-submit /home/hadoop/Experiment/Ex2_WordCount/WordCount.py
:warning: 如果启动了集群需要先关闭,因为本次实验并非在集群环境下运行:
1
2cd /usr/local/hadoop
sbin/stop-all.sh1
2cd /usr/local/spark
sbin/stop-all.sh查看结果
你应该得到如下结果:

3.3 visualize.py
在本节你应该完成对visualize.py 核心代码编写。
3.3.1 完成编码
可在服务器上查看visualize.py 文件如下:
visualize.py 一共有3个函数,它们的作用如下:
rdd2dic: 将resRdd转换为python Dic,并截取指定长度topKdrawWorcCloud:进行词云可视化,同时保存结果drawPie: 进行饼图可视化,同时保存结果
rdd2dic
完成下面指定位置编码,将resRDD转换为python Dic ,并截取指定长度
1 | def rdd2dic(self,resRdd,topK): |
3.3.2 提交代码
此时主函数代码,设置可视化为True:
1 | if __name__ == '__main__': |
切换到
spark目录1
cd /usr/local/spark
提交代码
依旧强调,非特殊说明不要在root用户执行代码,可能会出现以下错误:
“ERROR:zygote_host_impl_linux.cc (90)] Running as root without —no-sandbox is not supported.“
本次操作是在hadoop用户下。
1
bin/spark-submit /home/hadoop/Experiment/Ex2_WordCount/WordCount.py
问题解决
[ERROR#1] selenium. common. exception. webdriver exception: message: chrome not reachable
通常是因为chromedriver程序占用了端口,控制台登陆重启服务器即可。相关讨论可见 issue#5 @lympassion
[ERROR#2] Operation not permitted
感谢a-fly-fly-bird 同学提供的解决方案。
jieba.cache操作不足 :PermissionError: [Errno 1] Operation not permitted: ‘/tmp/tmpg255ml7f’ -> ‘/tmp/jieba.cache’
这是因为 jieba 默认情况下在 /tmp 下存储缓存文件,然而不是 root 用户,权限不够。解决办法是修改默认缓存文件的目录,把缓存文件放在用户的目录下面。
1
vim /usr/local/lib/python3.6/site-packages/jieba/__init__.py
将self.tmp_dir 赋值为用户目录下的任意目录,如下图:

render.html权限不够 :Permission denied: ‘render.html’
修改render.html权限:
1
2cd /usr/local/spark
sudo chmod 777 render.html
[ERROR#3] 运行chromedriver生成echarts图片报错
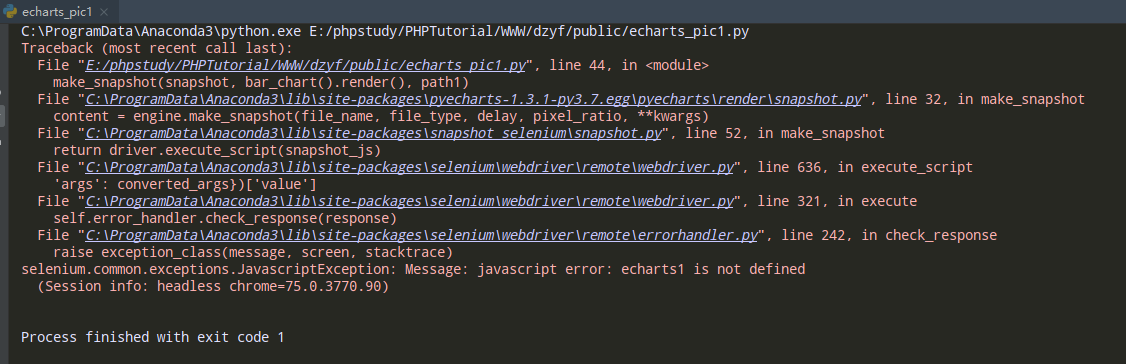
重新安装snapshot-selenium即可解决:
1
2pip3 uninstall snapshot-selenium
pip3 install snapshot-selenium
查看结果
查看目录
/home/hadoop/Experiment/Ex2_WordCount/results:
可以看出:
身高、家庭、性格、父母、学历等是青年群体择偶最在意的几个特质。
4 扩展实验
根据第2节:在本次实验我们给予学有余力的同学,在完成本次实验的基础上提出了扩展要求。
【注】加分后总分不超过100分。
| 扩展要求 | 加分 | 备注 |
|---|---|---|
| 1. 使用分布式完成本次实验 | +5 | 可参考ex3~ex4 |
| 2. 扩充原有数据集(100M以上),或基于新的数据集进行实验 | +5~+10 | 根据数据量、质量、难度给分 |
| 3. 新增更多可视化,如柱状图等 | +5~+10 | 根据可视化工作量给分 |
| 4.使用更好的算法分析数据,如应用深度学习模型Bert | +10 | 有对比实验更好 |
当然,如果你有更好的idea来完善更新本次实验,请联系老师或助教,我们还会考虑为你申请本年度的优秀课设(每一年都有同学通过该方式获得优秀课设)。
详情你可参考:CQU_bigdata-开源贡献。
5 实验小结
本次实验中你使用Hadoop&Spark编写了自己第一个项目,相信你一定有所收获。当然,你还体验了下远程开发的快感。
接下来的实验,你将会进一步学习在分布式集群下进行大数据分析,如:在集群执行任务、hdfs的使用等。同时你也将开始了解基本机器学习算法在大数据分析的应用,这将包括 Kmeans、SVM 等经典机器学习算法。
我们将尽量设计有趣、生动的实例来帮助你理解。最后,恭喜你完成第一个在基于Spark平台的大数据分析小项目,希望你从中获得了不少乐趣 :) 。
